Bayesian models for document classification
each instance = a doucument
intstance’s class = the document’s topic
document classification
각 단어에 대해 추가하거나 삭제한다.
ex) beautiful -> beau, pf -> professor
document = 단어의 가방이라고 볼 수 있다.
각각의 document의 길이는 다 다를 수 있는데
다 같다고 가정을 한다.
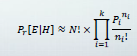
이 식을 보자
Pi = 각 단어들의 확률
E = document
H = 범주중의 하나
Ni = i 인덱스에 대한 확률
document topic 에 대한 probability 중에서 가장 큰 값을 가지는 것을 선택
예를 들어보자.
document topic 에 ‘yellow’ 와 ‘blue’가 있다고 가정하자.
class H에서는

의 값을 가진다.
document E = {blue, yellow, blue}
길이 N = 3
이 3단어의 경우의 수를 살펴보자.
순서는 상관없다
1
2
3
4
5
6
7
8
9
{blue, blue, blue} = 3! * (0.75)^0/0! * (0.25^3)/3!
{yellow, yellow, yellow} = 3! * (0.75^3)/3! * (0.25^0)/0!
{blue, yellow, yellow} = 3! * (0.75^2)/2! * (0.25^1)/1!
{blue, blue, yellow} = 3! * (0.75^1)/1! * (0.25^2)/2! = 14%
이 4가지의 경우의 수가 나온다.
각각의 확률은 위의 식을 계산하면 나온다.
class H 에서 {blue yellow blue} = 14%
이제 class H’ 를 보자

1
2
3
4
5
6
7
8
9
{blue, blue, blue} = 3! * (0.1)^0/0! * (0.9^3)/3!
{yellow, yellow, yellow} = 3! * (0.1^3)/3! * (0.9^0)/0!
{blue, yellow, yellow} = 3! * (0.1^2)/2! * (0.9^1)/1!
{blue, blue, yellow} = 3! * (0.1^1)/1! * (0.9^2)/2! = 24.3%
이런 확률이 나오게 된다.
{blue, blue, yellow} 경우에는
h = 14%
h’ = 24.3%
이기 때문에 h’ 범주에 속한다.
왜? h’ 의 %가 더 높게 나왔기 때문이다.
ZeroR
ZeroR은 다수의 클래스 값으로 new instance를 예측하는 것이다.
weather domain 에서 yes가 9번, no가 5번 나왔다.
따라서 new instance에 대해서 yes로 recommendation을 하게 된다.